Traceable Scientific Publication Infrastructure
Structured publication data
with clear provenance
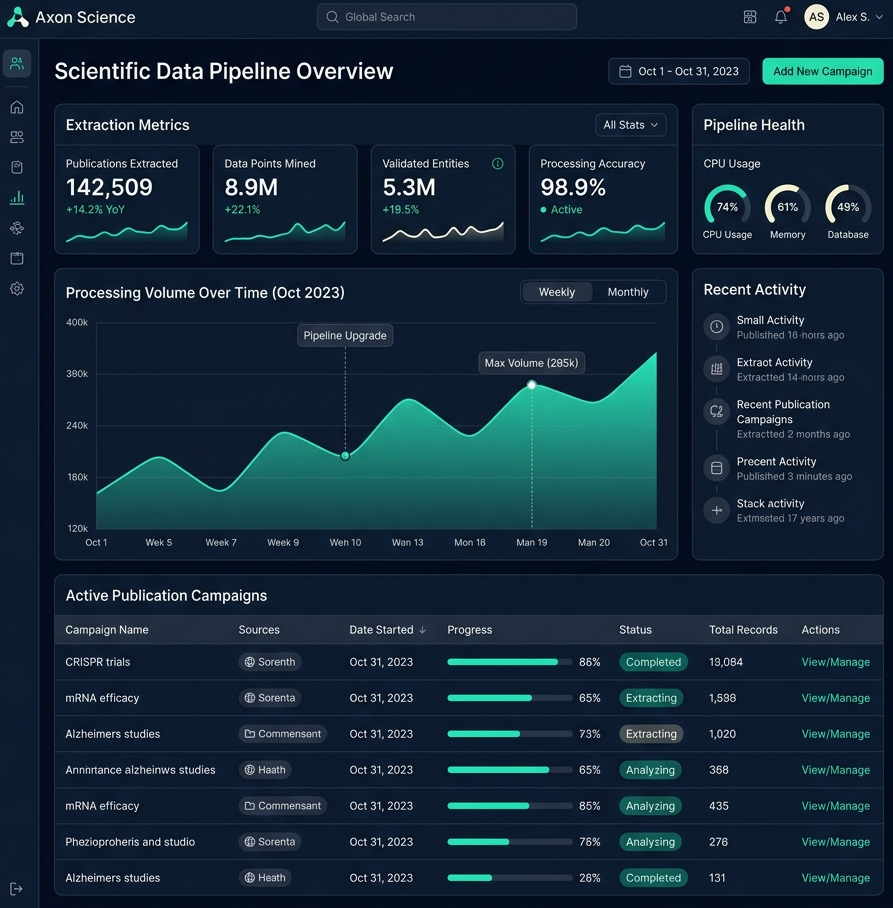
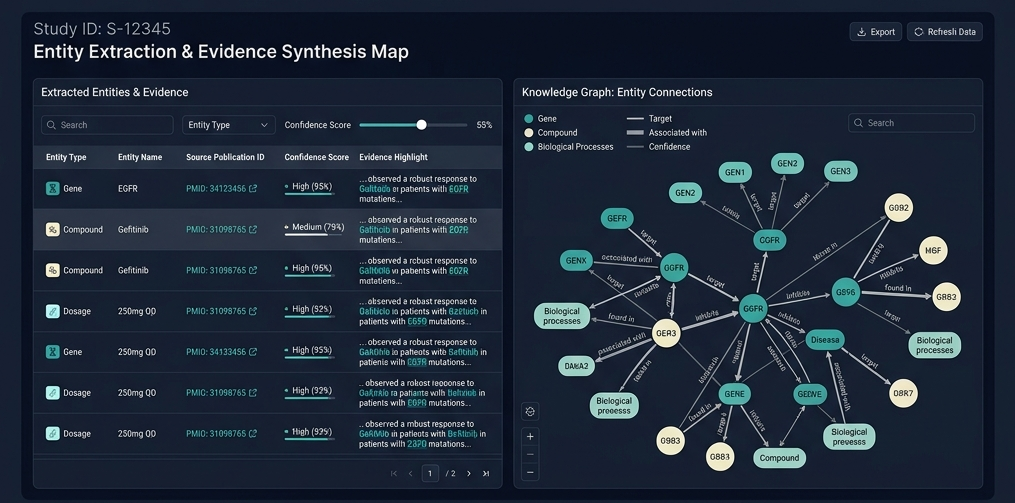
Onitum helps research and product teams transform papers, abstracts, and registry records into source-linked datasets. Our focus is straightforward: normalized identifiers, reviewable extraction outputs, and workflows that stay auditable from ingest to delivery.
DOI
Persistent identifier support
PMID
Literature indexing compatibility
NCT
Trial registry linkage when available
Designed for teams that need usable data and a defensible record of where every field came from.